Publications
Journal articles
2023
-
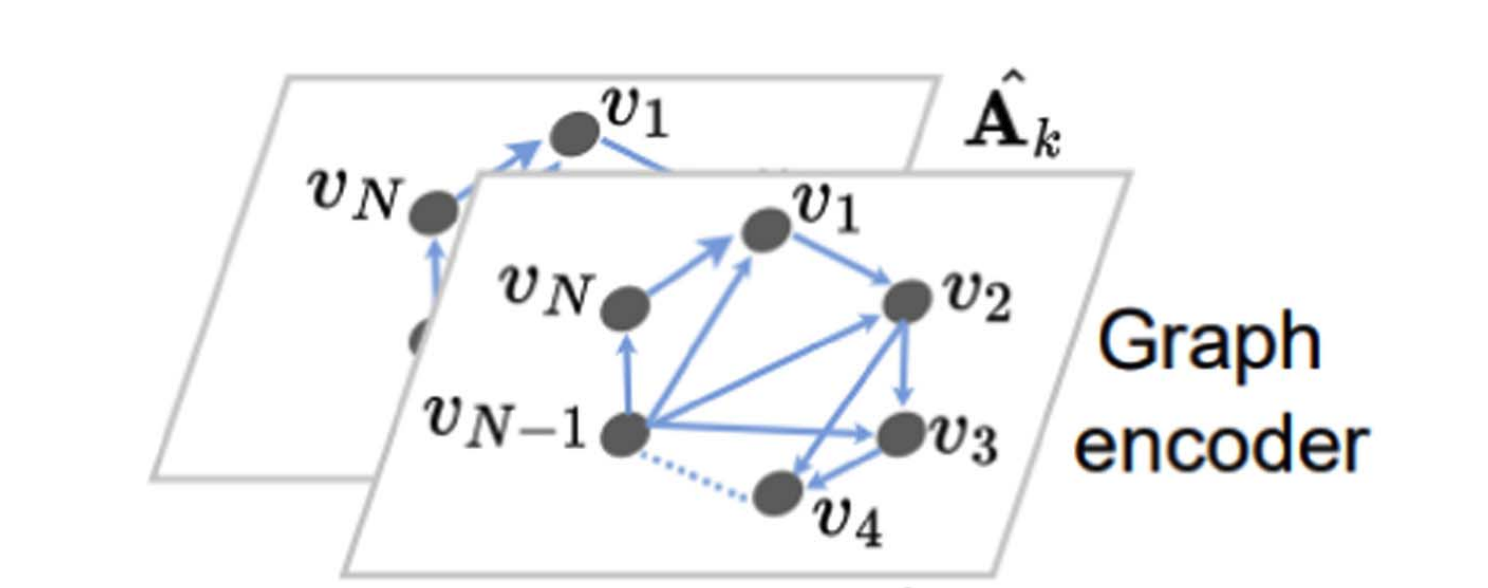 Time-Domain Speech Separation Networks With Graph Encoding AuxiliaryIEEE Signal Processing Letters, 2023
Time-Domain Speech Separation Networks With Graph Encoding AuxiliaryIEEE Signal Processing Letters, 2023
2022
-
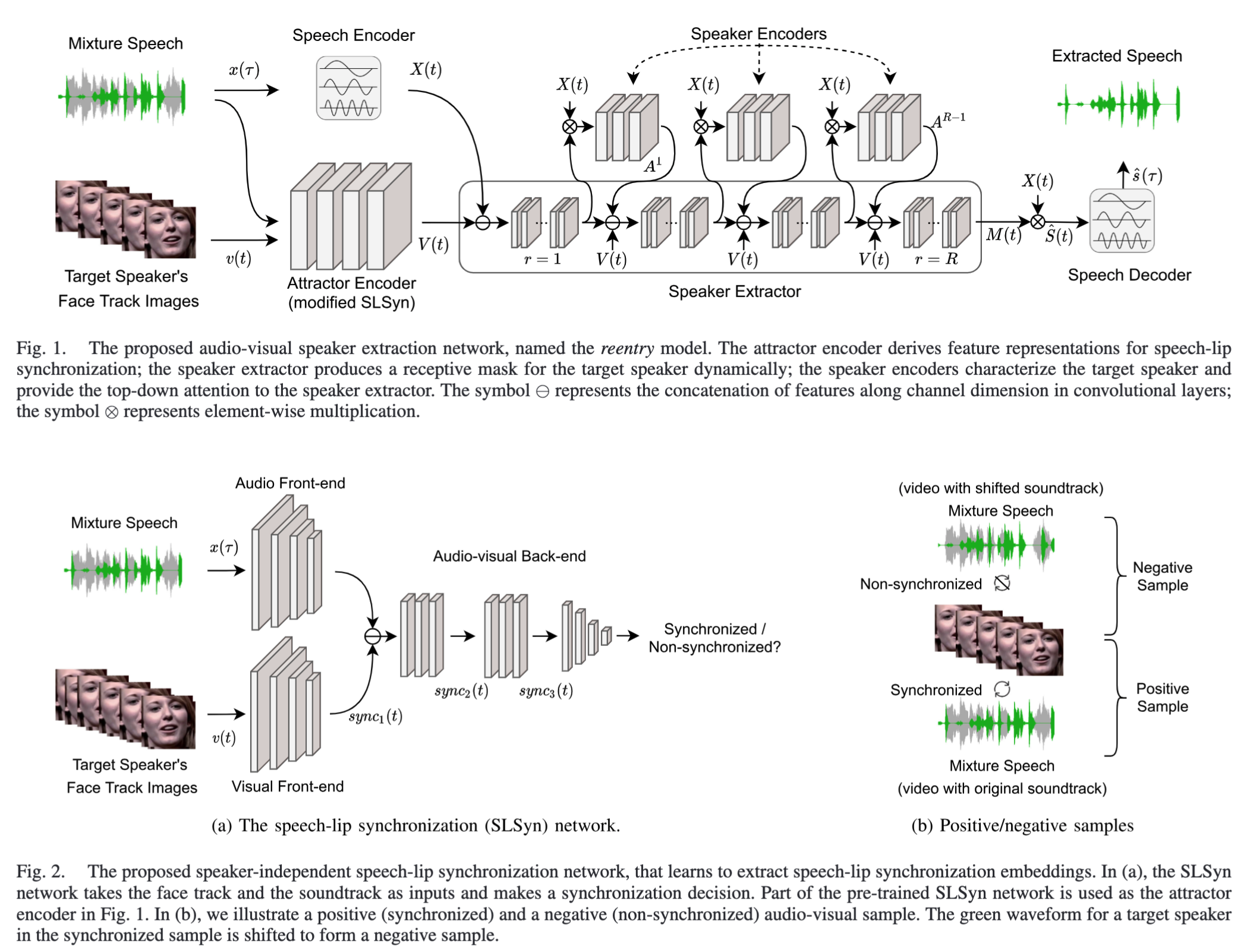 Selective Listening by Synchronizing Speech with LipsIEEE/ACM Trans. Audio, Speech, Lang. Process., 2022
Selective Listening by Synchronizing Speech with LipsIEEE/ACM Trans. Audio, Speech, Lang. Process., 2022
-
 USEV: Universal Speaker Extraction With Visual CueIEEE/ACM Trans. Audio, Speech, Lang. Process., 2022
USEV: Universal Speaker Extraction With Visual CueIEEE/ACM Trans. Audio, Speech, Lang. Process., 2022
Conference proceddings
2023
-
 ImagineNet: Target Speaker Extraction with Intermittent Visual Cue Through Embedding InpaintingIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2023
ImagineNet: Target Speaker Extraction with Intermittent Visual Cue Through Embedding InpaintingIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2023
-
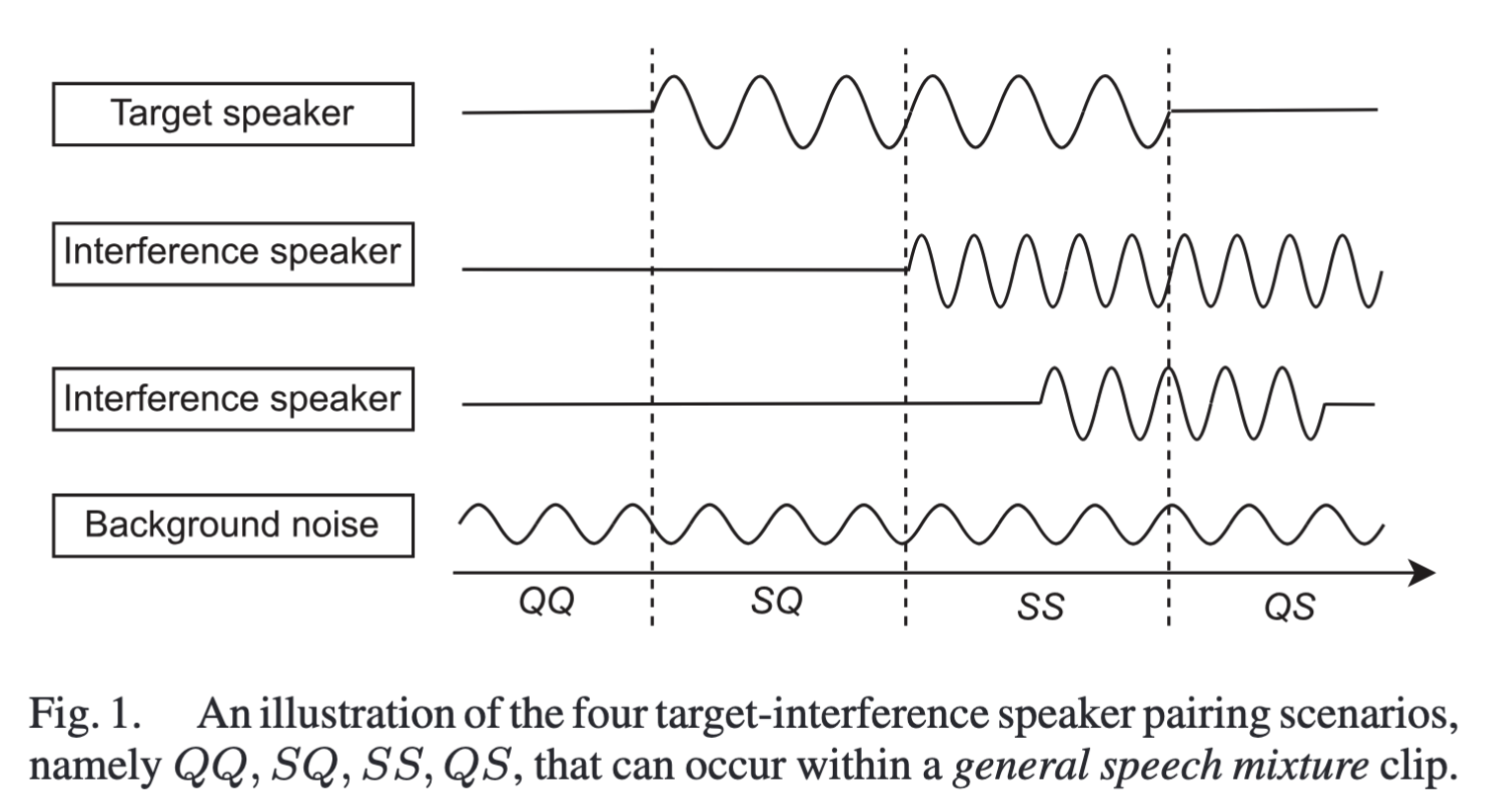
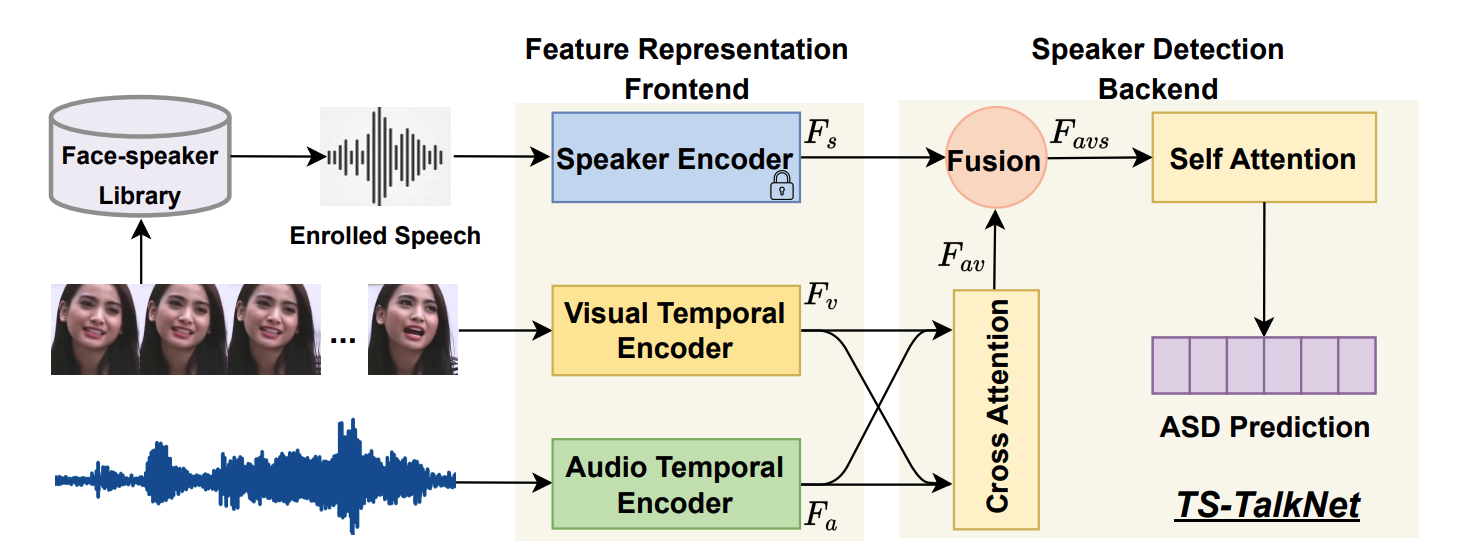
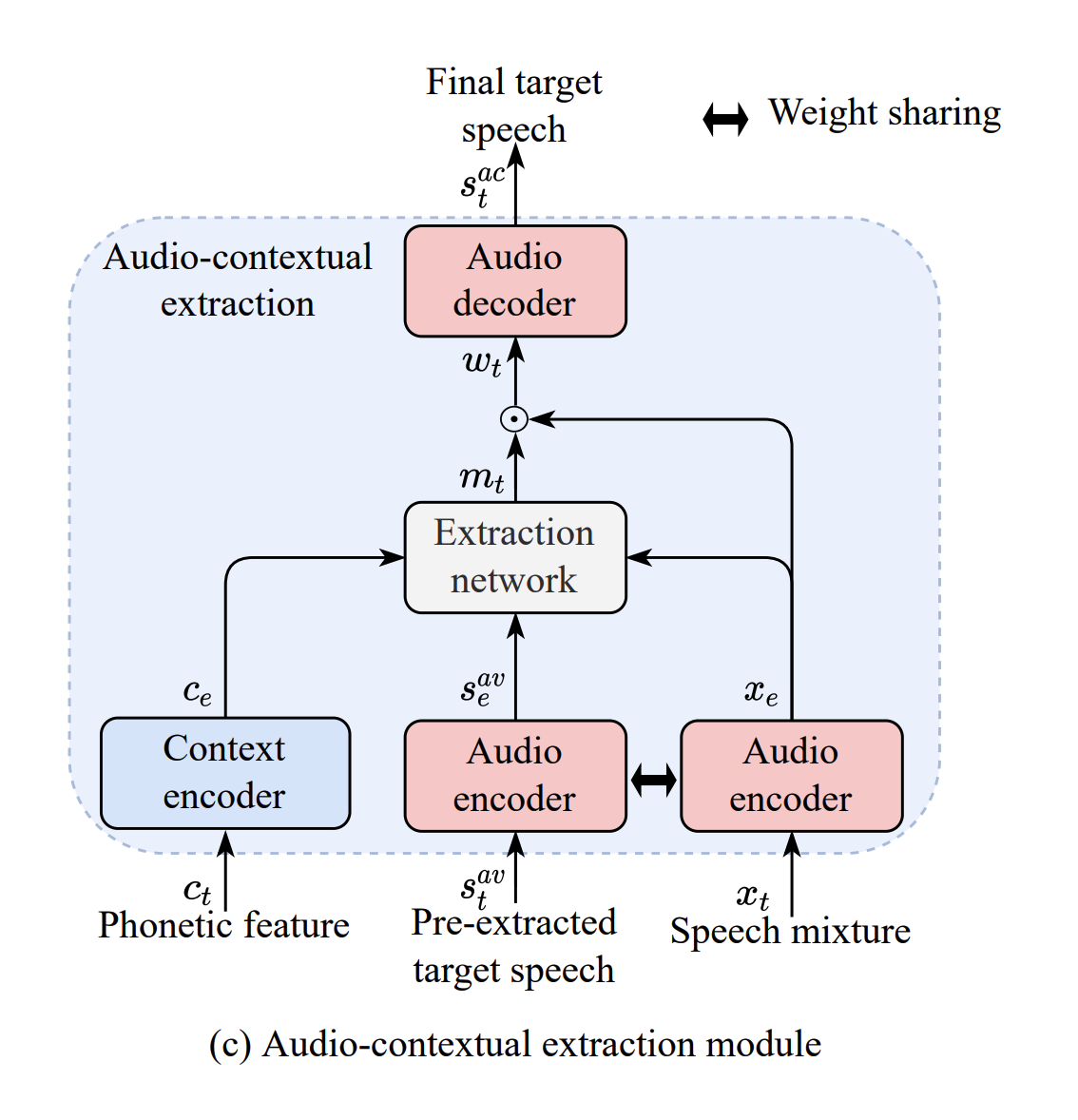
 Speaker Extraction with Detection of Presence and Absence of Target SpeakersIn Proc. INTERSPEECH, 2023
Speaker Extraction with Detection of Presence and Absence of Target SpeakersIn Proc. INTERSPEECH, 2023
2022
-
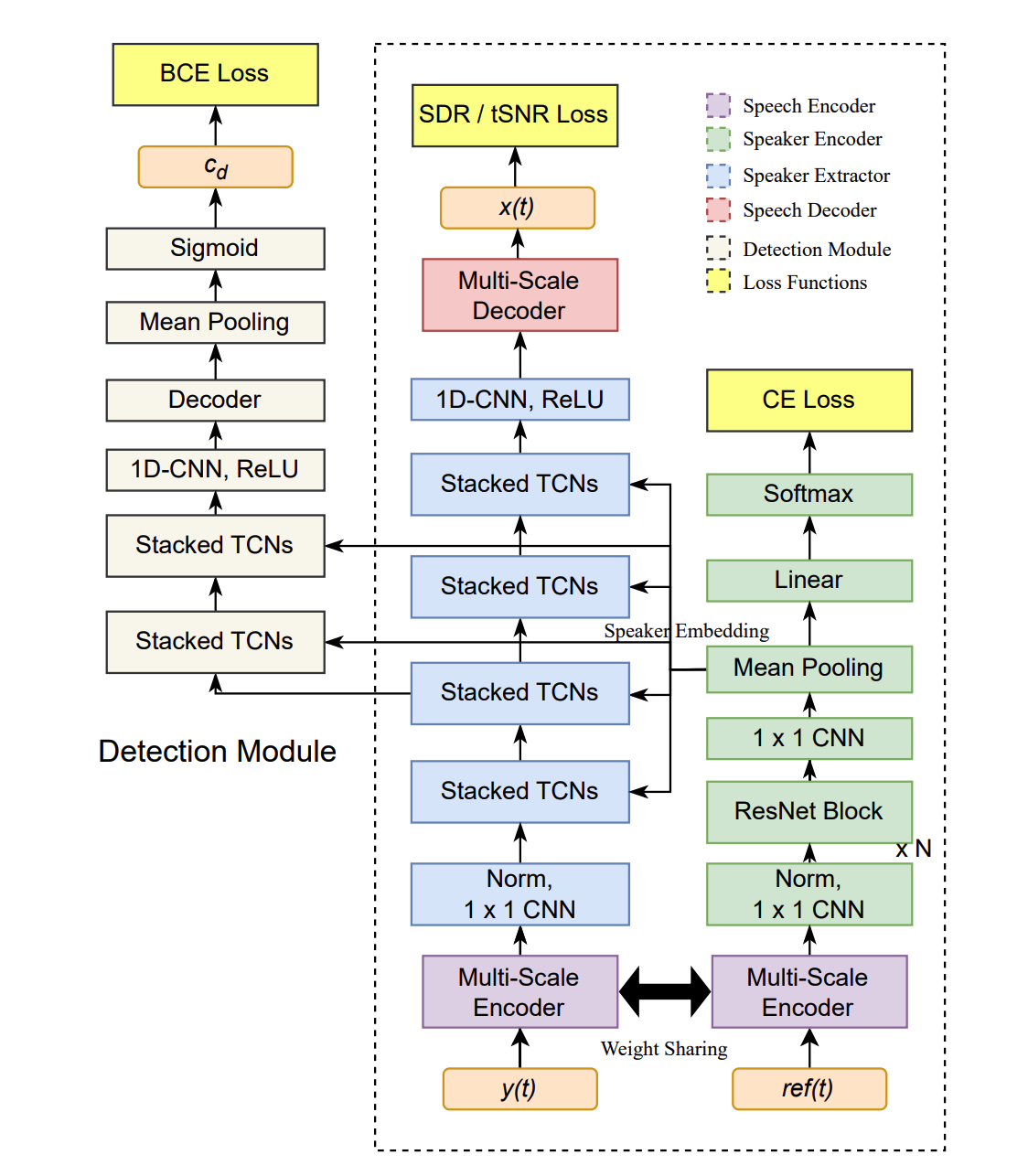
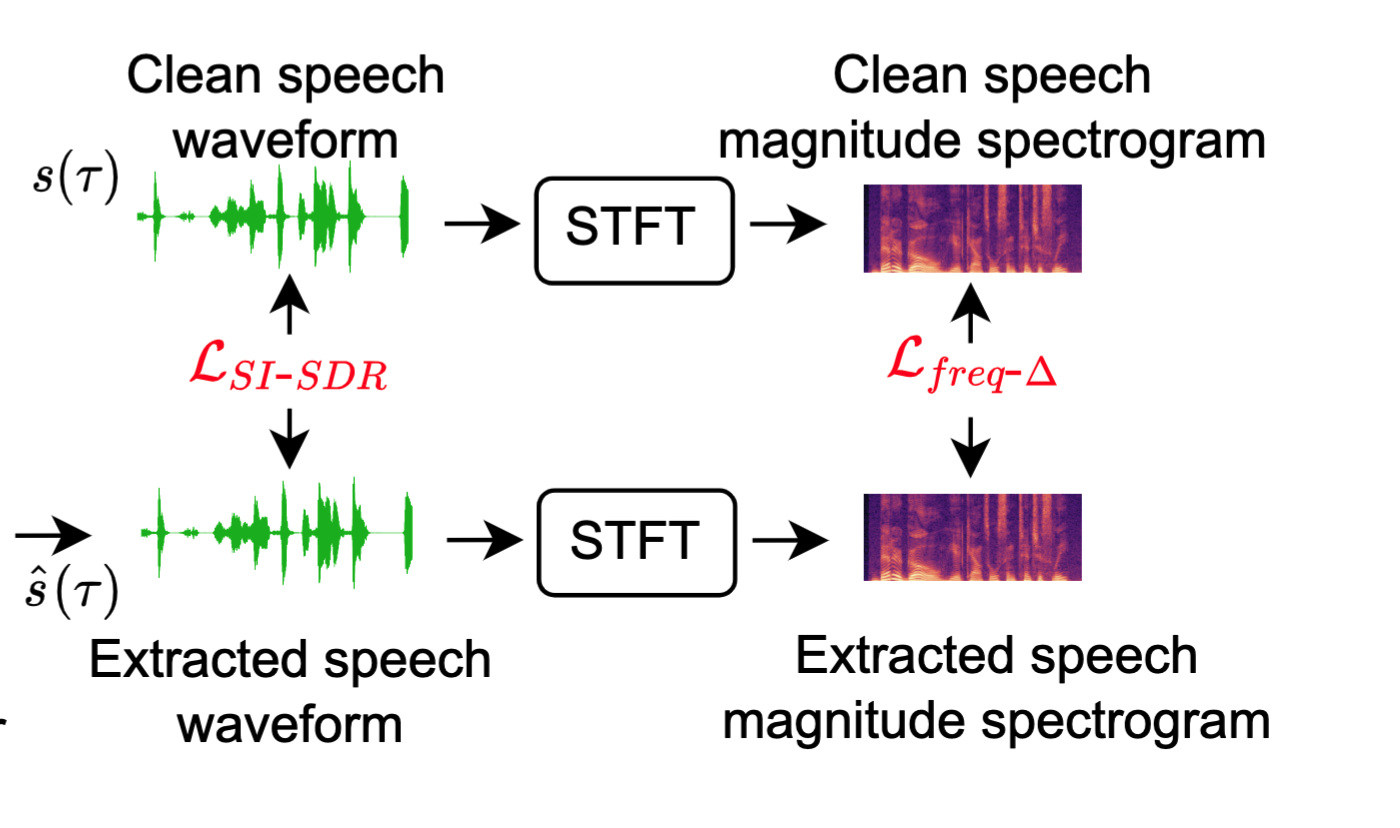 A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker ExtractionIn Proc. INTERSPEECH, 2022
A Hybrid Continuity Loss to Reduce Over-Suppression for Time-domain Target Speaker ExtractionIn Proc. INTERSPEECH, 2022
2021
-
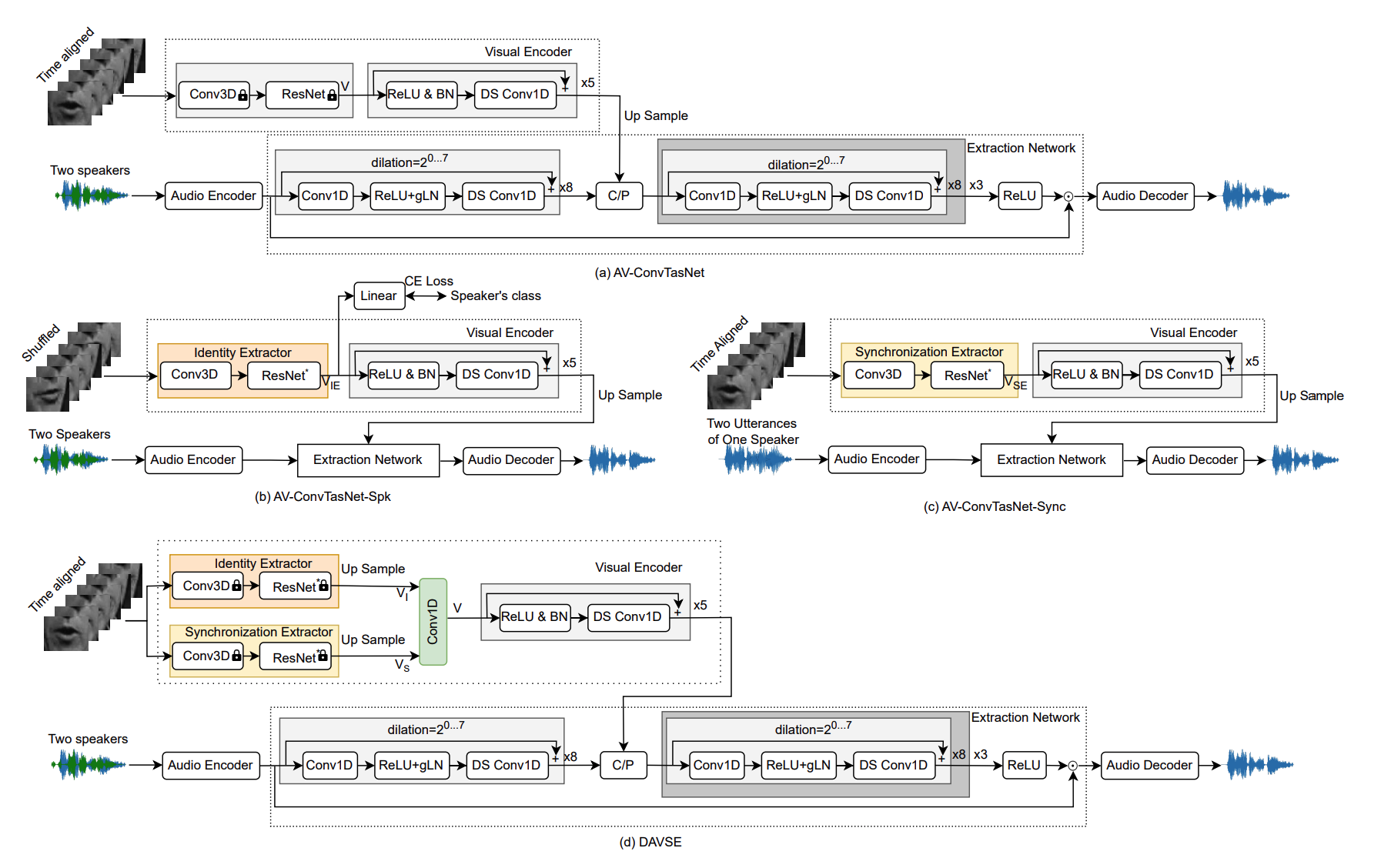
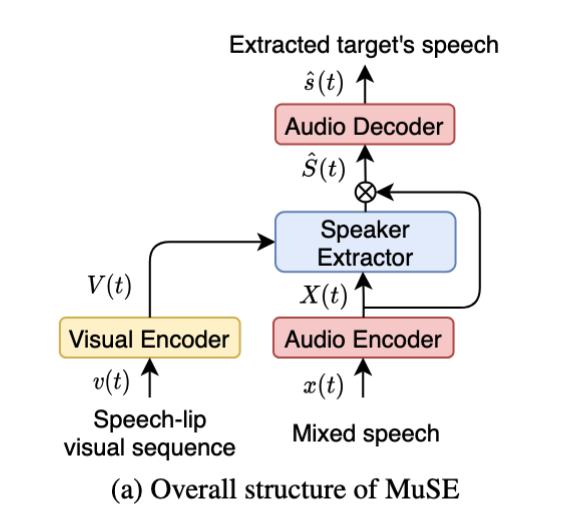 Muse: Multi-Modal Target Speaker Extraction with Visual CuesIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2021
Muse: Multi-Modal Target Speaker Extraction with Visual CuesIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2021
-
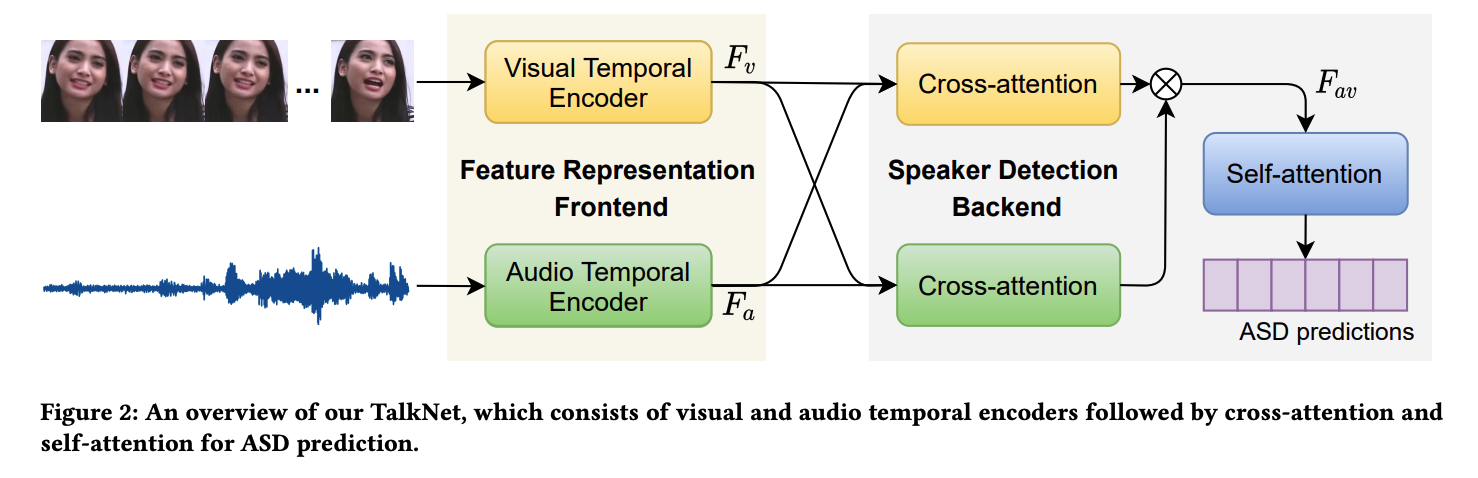 Is Someone Speaking? Exploring Long-term Temporal Features for Audio-visual Active Speaker DetectionIn Proc. of the 29th ACM Int. Conf. on Multimedia, 2021
Is Someone Speaking? Exploring Long-term Temporal Features for Audio-visual Active Speaker DetectionIn Proc. of the 29th ACM Int. Conf. on Multimedia, 2021
-
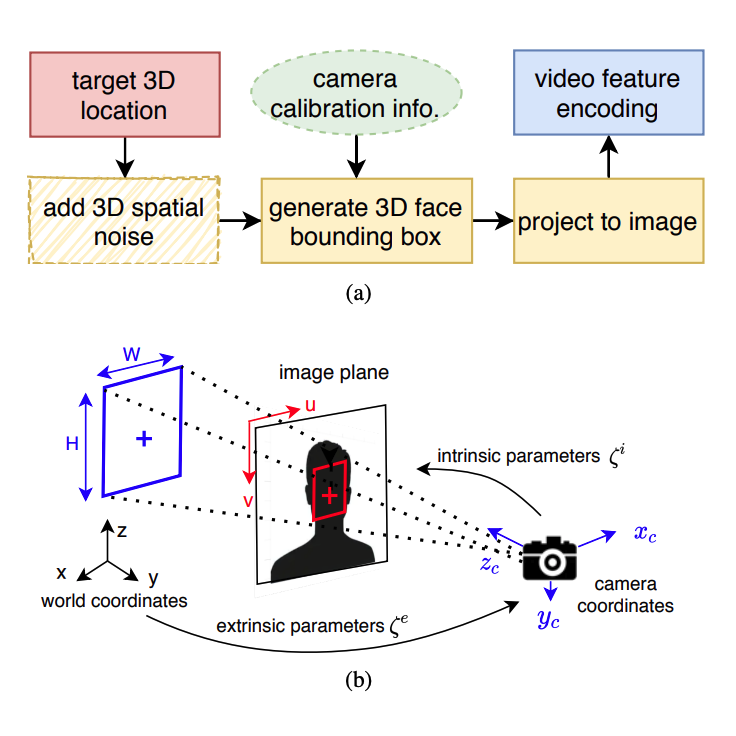 Multi-target DoA Estimation with an Audio-visual Fusion MechanismIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2021
Multi-target DoA Estimation with an Audio-visual Fusion MechanismIn Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2021
2020
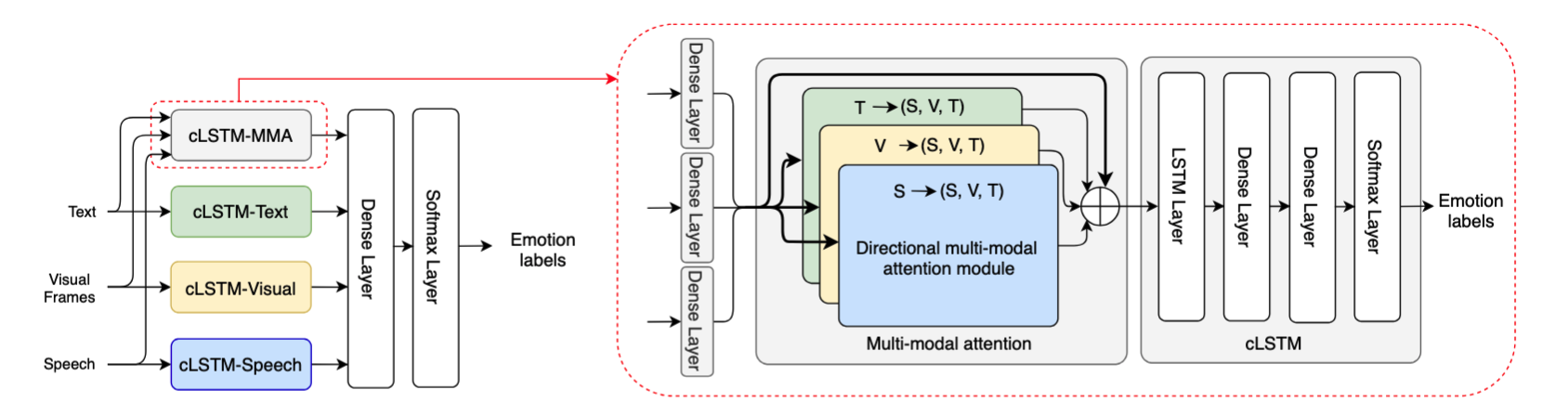
ArXiv Preprint
2023
-
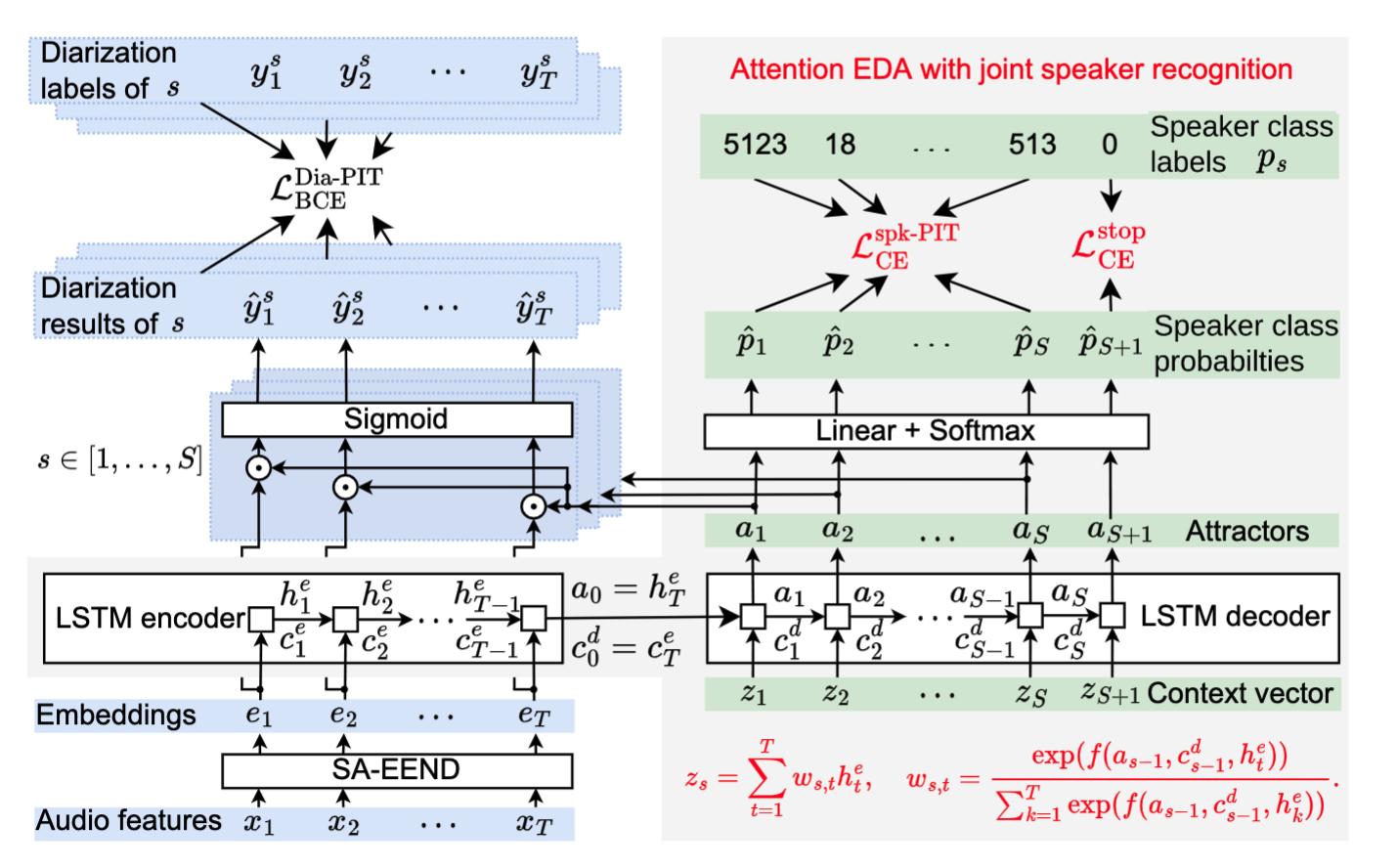 Towards End-to-end Speaker Diarization in the WildSubmitted to Autom. Speech Recognit. Understanding Workshop, 2023
Towards End-to-end Speaker Diarization in the WildSubmitted to Autom. Speech Recognit. Understanding Workshop, 2023